
Abbiamo detto, poco sopra, che Git confronta i file presenti nella working copy rispetto al commit da cui sono stati estratti per capire in che stato si trovano. Più frequentemente, però, sentiremo dire (e inizieremo a dire anche noi) che le eventuali modifiche presenti nella working copy sono rispetto a un branch su cui sto lavorando.
Proviamo a fare chiarezza.
Sappiamo che un commit è per Git uno snapshot del contenuto del repository in un dato momento. Sappiamo che ogni commit ha un riferimento al commit che lo ha preceduto. In questo modo, la sequenza di commit collegati l’uno all’altro ci permette di conoscere e ricostruire l’intera cronologia del progetto.
Supponiamo di aver portato avanti un progetto fino al rilascio della sua versione 1.0. Siamo pronti a lavorare a nuove fantastiche funzioni in vista della versione 2.0 tra qualche mese, ma, nel frattempo, magari potremmo dover fare dei rilasci “di fix” della versione 1 (1.1, 1.2, …). Come può facilitarci la vita Git
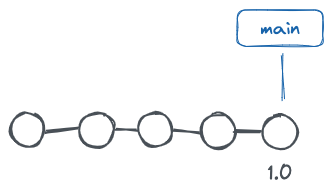
Fig – Commit su branch main fino alla versione 1.0
Quando abbiamo creato nel nostro progetto un repository con git init, Git ha anche creato un branch di default (il cui nome solitamente è main o master).
Man mano che abbiamo salvato i vari snapshot, ci è sembrato di “aggiungere” nuovi commit a questo branch, come se il branch main fosse composto dalla sequenza di commit.
In realtà, un branch in Git è un puntatore a uno specifico commit, un puntatore con un super potere: nel momento in cui viene effettuato un nuovo commit, il puntatore si sposta dal commit precedente all’ultimo.
Nel nostro esempio, potremmo creare un nuovo branch che punta al commit con cui abbiamo contrassegnato la versione 1.0 – notare che più branch possono puntare allo stesso commit – per le versioni di manutenzione 1.x

Fig – Nuovo branch punta a stesso commit
Poiché ogni branch punta a un commit – tale commit è indicato come “tip” o “head” del branch stesso – e, poiché Git sa il commit e il branch da cui è stata estratto l’attuale contenuto della working copy, nel momento in cui si aggiunge un commit, questo diventa la nuova “head” del branch.
In pratica, nel nostro progetto di esempio, potremo avere due commit “figli” dello stesso commit che contrassegna la versione 1.0, ognuno nei rispettivi branch, dando vita a due history separate.

Fig – Due branch, due history
Ciò che è importante è, quindi, avere sempre chiara la distinzione tra ciò che facciamo nel pratico con Git (“estrarre un branch nella working copy” oppure “vedere la cronologia di un branch” oppure “vedere le modifiche dell’ultimo commit”) e ciò che internamente fa Git (“estrarre nella working copy il commit (snapshot) che è la HEAD di un branch” oppure “partire dalla HEAD di un branch e ricostruire tutti i commit genitori” oppure “mostrare le differenza tra l’ultimo commit (snapshot) e il suo genitore (snapshot)”).
È importante annotare che Git non è prescrittivo sulle modalità d’uso dei branch, sta quindi ai team scegliere se e come sfruttare i branch per le proprie necessità. Nel tempo sono state promosse e definite alcune “branch strategies” più comuni, basate sull’uso di branch e sulla possibilità offerta da Git di “spostare” da un branch a un altro i commit.
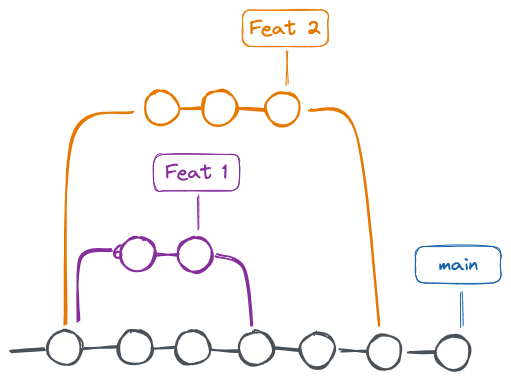
Fig – Feature branch


