
Nella sezione introduttiva abbiamo detto che uno dei vantaggi di Git è quello di proporre un modello di collaborazione distribuito. Abbiamo anche già spiegato come “recuperare” un progetto preesistente ospitato su un server remoto tramite il comando git clone.
Entriamo più nel dettaglio nell’uso di un repository remoto da parte di più collaboratori, partendo dal modello più semplice, quello del “repository condiviso”.
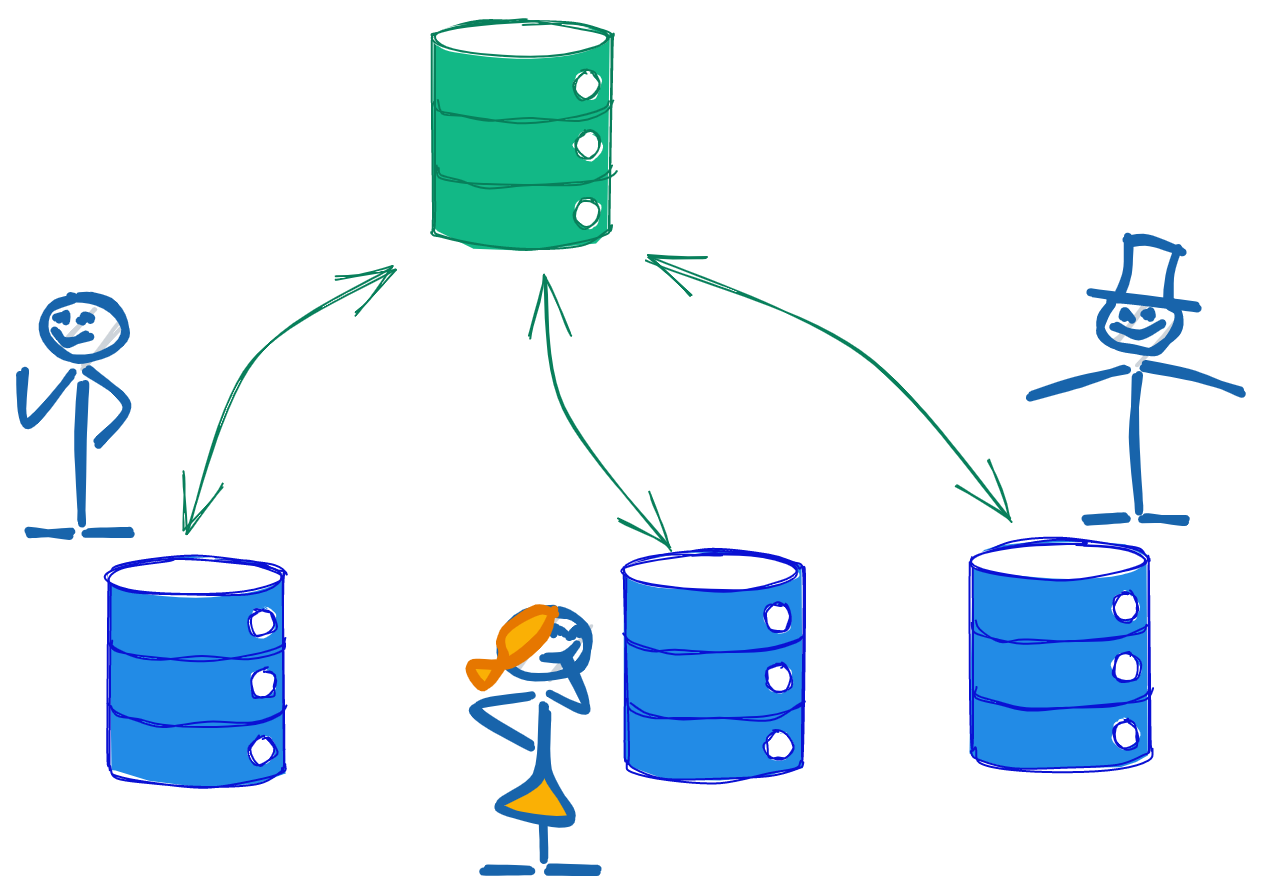
Repository condiviso
La modalità di collaborazione più semplice realizzabile tramite Git è quella che è indicata come “modello shared repository”.
Nella pratica, poiché un repository Git contiene l’intera cronologia del progetto, in questa modalità esiste un repository condiviso collocato su un computer remoto raggiungibile da tutti i collaboratori che viene usato per recuperare o inviare nuovi commit.
I singoli web developers collaboratori recuperano sui propri computer una copia locale del repository remoto condiviso tramite il comando git clone. I commit aggiunti dai singoli collaboratori sulle proprie copie locali possono essere inviati alla copia remota condivisa tramite il comando git push. I commit aggiunti da altri collaboratori alla copia remota condivisa possono essere recuperati e riportati nella propria copia locale tramite i comandi git fetch e git pull.
In questo modo il repository remoto condiviso agisce da “master copy” (la versione originale di un contenuto, per esempio un album musicale o un film da cui vengono realizzate copie, NdR) della history del repository, ovvero è la history originale e ufficiale del repository a cui tutti possono attingere.
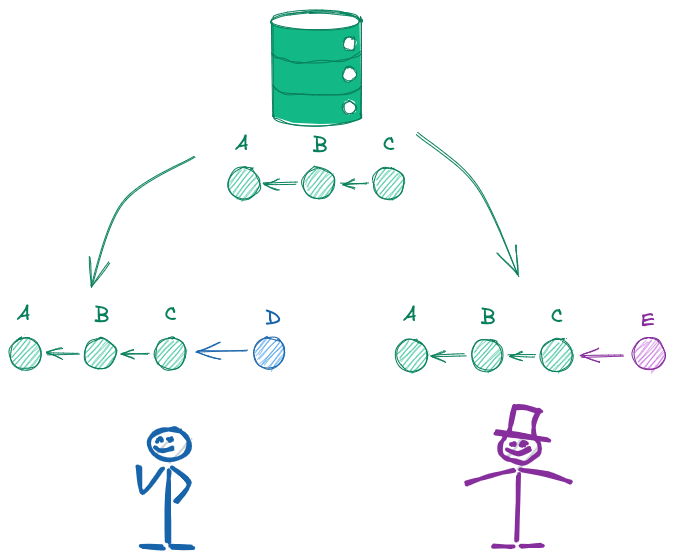
History originale
Ovviamente, nelle operazioni di invio e recupero di nuovi commit, entra in gioco l’altra caratteristica fondamentale di Git, cioè la salvaguardia delle modifiche delle history. Nel caso rappresentato dell’immagine qui sopra due collaboratori hanno aggiunto entrambi un commit (rispettivamente D ed E) alla stessa sequenza di commit (A-B-C) recuperata da un repository remoto.
In tale situazione, la history dei due repository locali sono “localmente” corrette. Entrambi sanno di avere un commit in più rispetto al repository remote ed entrambi possono potenzialmente inviare il proprio commit in più al repository remoto.
Nel momento in cui uno dei due collaboratori invia il suo commit al repository remoto originale, la situazione cambia.
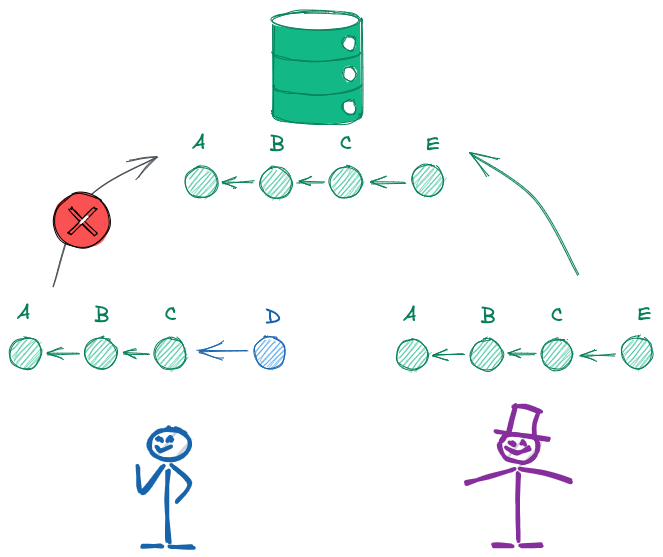
You shall not push
Una volta che il commit del collaboratore col cilindro (E) è entrato a far parte del repository remoto originale, non sarà più possibile all’altro collaboratore inviare il proprio commit (D) al repository remoto. Per Git infatti un commit non è composto solo dalle modifiche apportate ai file che fanno parte del progetto, ma è uno snapshot all’interno di una sequenza di snapshot.
Il collaboratore senza cilindro ha quindi due opzioni:
- recupera dal repository remoto la history aggiornata (A-B-C-E), aggiunge a questa il suo commit e poi invia al repository remoto
- forza l’invio della sua history (A-B-C-D) al repository remoto, sovrascrivendo e quindi cancellando ogni traccia del commit E dal repository remoto
La seconda opzione è, ovviamente, quella da non fare in situazioni normali. Git permette la sovrascrittura della history, ma va fatta solo quanto veramente e cioè per correggere qualcosa, non per vanificare il lavoro di altri.
Quanto alla prima opzione, esistono diverse situazioni possibili nel momento in cui si recupera la history remota aggiornata e si riporta sulla propria copia locale che vedremo nelle successive sezioni.
Una annotazione finale: ovviamente il repository remoto condiviso è usato anche per tenere sincronizzati branch e tag


