
Abbiamo visto, all’inizio di questa sezione, come recuperare nuovi contenuti da un repository remoto tramite il comando git fetch. Vediamo ora più nel dettaglio come riportare tali modifiche nella propria working copy tramite il comando git pull.
L’unione delle modifiche dal repository remote al repository locale è un’attività comune nei flussi di lavoro di collaborazione basati su Git. Il comando git pull in Git viene spesso utilizzato per recuperare e scaricare contenuti da un repository remoto e aggiornare immediatamente la working copy del repository locale in modo che corrisponda a tale contenuto.
Il comando git pull in Git è, in realtà, una combinazione di altri due comandi.
Nella prima fase dell’operazione git pull eseguirà un git fetch limitato al solo branch a cui punta la propria working copy. Una volta scaricato il contenuto, git pull entrerà in un flusso di riconciliazione dei commit che potrà seguire due modalità dagli effetti ben diversi.
Proviamo a capirlo meglio con un esempio.
Supponiamo di aver clonato un repository remoto quando l’ultimo commit sul suo branch main era quello indicato come “B”. Abbiamo fatto delle modifiche e abbiamo salvato in locale i commit “C”, “D” ed “E”. Nel frattempo, qualcun altro, ha creato a inviato al repository remoto altri commit, “F”, “G” e “H”
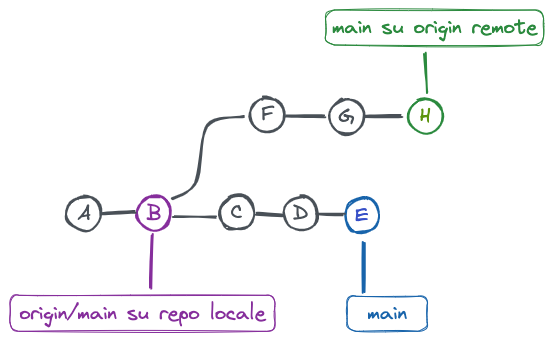
Stato iniziale esempio merge
In questa situazione, considerando che il repository remote è quello che ospita la storia “ufficiale” del progetto, dovremo recuperare i nuovi commit remoti e integrarli con quelli locali. Dovremo, però, anche indicare la strategia preferita con cui farlo.
Git, infatti, offre due modi ben distinti con cui effettuare pull/merge di branch divergenti, con rebase o con merge.
NOTA: nelle recenti versioni di Git l’esecuzione di git pull su branch divergenti non viene completata a meno che non si sia indicata la strategia desiderata. È possibile farlo tramite gli argomenti del comando, ma è anche possibile indicare la strategia di default tramite git config.
Pull con rebase
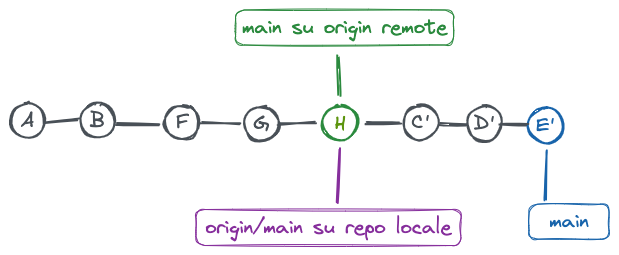
Stato iniziale esempio merge
Il pull con rebase è la modalità che, in un certo senso, rispetta come “ufficiale” il contenuto del repository remoto e considera i commit nel repository locale come commit da applicare sulla history aggiornata del repository.
Eseguendo git pull –rebase succede, in pratica, quanto segue:
- vengono messi da parte i commit locali (C-D-E) aggiunti rispetto all’ultimo origin/main recuperato
- viene eseguito il fetch che recupera i nuovi commit dal branch main del repository remoto origin
- i nuovi commit remoti vengono applica alla “copia” locale origin/main e viene aggiornato il branch locale main e la working copy
- i commit locali C-D-E vengono “riapplicati”, creando quindi i nuovi commit C’-D’-E’, ciascuno dei quali contiene le stesse differenze dei commit C-D-E
Ricordiamo, infatti, che un commit è uno snapshot completo dello stato di un repository, quindi avendo cambiato la storia precedente al commit C, il commit C’ conterrà le stesse “differenze” rispetto allo snapshot precedente, ma sarà, nella pratica, un nuovo commit.
È possibile scegliere questa strategia come default tramite il comando git config pull.rebase true
Pull con merge
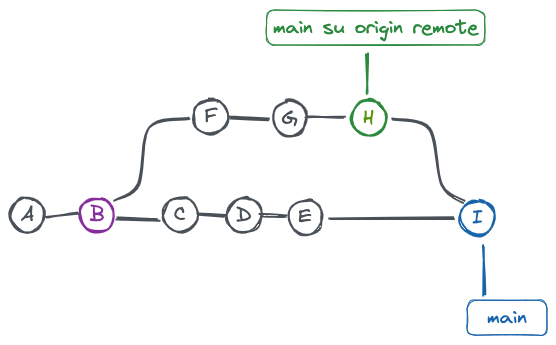
Stato iniziale esempio merge
L’altra modalità è quella di pull con merge che, nella situazione descritta, dà la “precedenza” al repository locale rispetto a quello remoto, o quanto meno nella situazione descritta potrebbe creare una history apparentemente poco coerente.
Eseguendo git pull –no-rebase succede, infatti, quanto segue:
- viene eseguito il fetch che recupera i nuovi commit dal branch main del repository remoto origin
- vengono presi i commit F-G-H recuperati dal repository remoto e viene creato uno speciale commit di “merge” (I) che applica l’intero diff al branch locale
- viene chiesto all’utente di salvare tale commit.
Alla fine del pull con merge, sebbene siamo in una situazione che dal punto di vista di Git non è più “divergente” (sarà, infatti, possibile fare git pull per inviare al repository remoto), la history del progetto risulta meno comprensibile e lineare.
Se, infatti, visualizziamo la history del progetto con git log –graph –oneline dopo aver effettuato il push, otterremo qualcosa del genere:
$ git log --graph --oneline * ece860f (HEAD -> main, origin/main, origin/HEAD) I - Merge branch 'main' of https://server.com/repository.git |\ | * 09817f7 H - remote commit three | * 1e0e1d2 G - remote commit two | * b7d7502 F - remote commit one * | 4d49b1c E - local commit 3 * | 6453336 D - local commit 2 * | 24540dd C - local commit 1 |/ * 9cc4eee B - another commit * f46646d A - initial commit
Notare che, dal punto di vista prettamente cronologico del repository remoto, è stata invertita la cronologia, poiché nella history i commit F-G-H erano, in pratica, già presenti prima che fossero inviati i commit C-D-E, che, invece, ora sono direttamente successivi ai commit A-B.
Sebbene, quindi, il “merge” sia una attività a volte necessaria nel gestire la sincronizzazione di lavori su Git, nel caso in cui si collabori ad un branch è consigliabile optare per la modalità con rebase.
È possibile scegliere questa strategia come default con il comando git config pull.rebase false


